SDLC & Software Management Skills Every Tech Guy Needs

Software development life cycle (SDLC) is a structured process to design, develop, and test good-quality software. Here are the stages of the SDLC:
Problem Identification (Cost Benefit Analysis)
Requirement Analysis (Interactive / Unobtrusive method to analyze the project)
System Analysis (CASE Tools, Activity and Framework selection, Process Modeling - Prototyping, Agile, RAD, XP, Scrum, V-type, Waterfall, Concurrent)
System Designing (App Architecture, Usecase, UML, Sequence, State chart Diagram etc.)
Development and Documentation (Pair programming, Code reviewing, Code refactoring, SOLID principle)
Testing and Maintenance (Unit testing, Integration testing, System testing, Acceptance Testing)
Implementation And Evaluation (Deployment strategy, Security enhancement, Bug reporting, Feedback analysis)
Interesting fact 😮😮😮
Time spent on maintenance typically ranges from 48-60 percent of total time
Problem Identification
For selecting a project in an organization, it must meet five criteria:
Backed by management
Having timed appropriate resources
It must move the business toward the attainment of its goal
Cost-effective
Important enough to select over other projects
Cost Benefit Analysis
We want to gain more benefits from the project than from its development and running costs over time. In this scenario, we may be concerned about how long it will take to return the investment or the profit percentage compared with the initial investment.
Payback Analysis: Analysis that finds the unit of time when investors will get their money back.
$$payback \space period = total \space investment \div Annual \space cash \space flow$$
Net Present Value (NPV): This analysis calculates the difference between cash inflows and outflows over time. It’s unique because it uses the time-value perspective of the invested money and considers discounted cash flow reflecting risk, inflation, or opportunity cost.
$$npv = \sum^t_0 {cashflow \space X \space discounted factor}$$
Return on Investment: This analysis shows how much return you will get compared to the initial investment.
$$ROI = average\space net\space profit \space\div total \space investment$$
We should check the project’s feasibility before requirement analysis: a. Technical b. Economical c. Operational.
We must plan its high-level activities and estimated time in this planning phase. We can use the GANTT chart or PERT to get a rough idea of the estimated time for the whole project. Here is an example of a GANTT chart:

Requirement Analysis
To analyze the project's requirements, we must gather information from its stakeholders, documents, files, or the current system.
An analyst can gather information regarding the project based on two approaches: Interactive (Involvement of individuals) and Unobtrusive ( Sampling, Observing, Analyzing From files, documents, or current system behaviors / applying STROBE)
Question Types
Before collecting data, we must know that Information can be derived from two types of questions: Open-ended and closed-ended questions. Here are the significant differences between open-end and close-end questions:
| Aspects | Open-end | Close-end |
| Precision of Data | Low | High |
| Efficient use of time | Low | High |
| Reliability of Data | Low | High |
| Breadth and Depth | Much | Little |
| Interviewer Skill Requirement | Much | Little |
| Ease of Analysis | Difficult | Easy |
Question Arrangement
We can arrange questions in three exciting formats:
Pyramid (Close-end → Open-end): It’s a helpful technique when the responder needs to be warmed up about the topic.
Funnel (Open-end → Close-end): It’s useful when we want to connect emotionally with the responder by asking broad questions.
Diamond (Close-end → Open-end → Close-end): This is an excellent way to conduct an interview, but it takes more time than the Pyramid or Funnel structure.
An interactive way to collect information
Here are the ways to collect data from stakeholders of the project:
Interviewing:
To initiate an interview, we must study specific background material regarding the project. Then, we will establish the interview’s objectives. Next, we should decide whom to call for an interview. After that, we will prepare the interviewee. Now, we will set up a structure of questions (Pyramid, Funnel, or Diamond). Finally, we must close the interview by asking if the interviewee has something to talk about, summarizing and providing feedback, asking whom we should talk with next if required, asking for the following schedule if needed, and appreciating for joining the interview.
User stories:
Stories are a remarkable way to understand the underlying problems of the current system. But they take more time than interviews, and sometimes, listening to stories is not efficient enough.
JAD:
Joint Application Design is a process for collecting information regarding a project in a group-based session. It usually happens where we need to sit within a group to discuss and talk in an offsite location. If the Pre-planning and follow-up report are incomplete, such a meeting would not be fruitful.
Questionnaires:
We can collect data by filling out a questionnaire form. Electrical forms are cheaper and easy to store for future use.
After gathering all the information about the project, we must write an SRS (Software Requirement Specification) so that we can validate upon testing that this software meets all the requirements.
System Analysis
First, we should introduce ourselves with what is software actually.
Actually, software is a set of instructions (computer program) that, when executed, provides desired features, functions, and performance where the user can modify the data according to data structures and has its own documentation that describes its operation. And the software doesn’t wear out as much hardware because it doesn’t affect outer environment conditions.

For analyzing a system, we may need to know whether the estimated size of the project is large or small. Larger projects need three things - Efficiency of work, Reliability, Ease of Maintenance, and Guaranteed Performance. That’s why we use one kind of activity framework called Umbrella Activities.
Umbrella Activity
The core activities of this policy are shown below:
Formal Technical Interview
Software Project Management
Software Configuration Management
Software Quality Assurance
Work product preparation and production
Risk Management
Reusability
Measurements
Framework Activity
This activity is a good solution for small to mid projects because it only focuses on the below activities -
Communication
Planning
Modeling
Construction
Deployment
Now, let’s learn about process modeling, a structured way to develop software that aligns with a sequence of tasks and activities and sets up milestones and deliverables.
Interesting Fact 😮 😮 😮
Do you know the difference between Milestones and deliverables? Ans: Milestones are short-rewarding activities that are submitted to project manager and deliverables are required functionalities that are submitted to the client. All the deliverables are milestones but not all the milestones are deliverables.
Process Model
There are many software development models available. I have always preferred Scrum for long-term projects and Extreme Programming (XP) for complex projects.
Baseline Models Comparison
Here is a comparison table showing key aspects of the Waterfall, Incremental, and Concurrent process models:
| Aspect | Waterfall Model | Incremental Model | Concurrent Model |
| Development Approach | Linear | builds in increments | Parallel |
| Phases | Fixed (communication, planning, modeling, construction, and deployment) | Repeated waterfall phases for each increment | Activities overlap (none → under development → under review → baseline → done → awaiting changes → under revision) |
| Client Feedback | phase-end reviews | Regular feedback after each increment | Continuous feedback on parallel tasks |
| Risk Management | Low flexibility | Moderate | High adaptability |
| Suitable Projects | Stable requirements | Flexible projects (e.g., enterprise applications) | Complex, dynamic projects needing high adaptability (e.g., real-time systems, R&D) |
Efficient Models Comparison
Here’s a comparison table highlighting the differences between Agile Scrum, Agile Extreme Programming (XP), and the V-Model:
| Aspect | Agile Scrum | Agile Extreme Programming (XP) | V-Model |
| Development Approach | Time-boxed sprints | Frequent releases and updates | Sequential follows a V-shaped flow |
| Phases | Divided into sprints (e.g., sprint planning, development, sprint review, retrospective) | XP Planning (Stories) → XP Design (CRC card, KISS) → XP Coding (Unit test writing, Pair, refactoring) → XP Testing | Requirement, Architecture Design, Component Design, Code Generation → Unit, Integration, System, Integration Testing |
| Client Feedback | Regular feedback at the end of each sprint | Continuous feedback through frequent releases | Limited feedback, typically after each phase or after validation |
| Risk Management | Continuous adjustments, risk identified and mitigated each sprint | High adaptability, risks are addressed through continuous testing | High risk in early stages if changes occur late in development |
| Suitable Projects | Complex, evolving projects requiring collaboration (e.g., web apps, customer-facing products) | Highly flexible projects with changing requirements (e.g., software tools, utilities) | Well-defined requirements, safety-critical or regulated projects (e.g., healthcare, avionics) |
Picture time for process modeling





Basic Estimation using LOC
Proper cost estimation is a multi-variant strategy for running a sustainable business. Without proper software design analysis, we cannot arrive at a logical costing of developing the software as we need people, a set of skills, identification of OTS and non-OTF components, tools, hardware, and network resources.
LOC means Line of code. Based on LOC and the cost of the person-month strategy, we can estimate a cost for a specific software. To do this→
- Functional decomposition of the requirements
Estimate the size of each function LOC
Example Table:
| Feature Name | Short Description | LOC (Optimistic) | LOC (Most Likely) | LOC (Pessimistic) |
$$Total \space LOC = (\frac{{\text{LOC_Optimistic} + 4 \times \text{LOC_Most_Likely} + \text{LOC_Pessimistic}}}{6})$$
Calculate the price
$$[ \text{Effort} = \frac{\text{Total LOC}}{\text{Productivity Rate}} ]$$
$$[ \text{Estimated Cost} = \text{Effort} \times \text{Labour Rate} ]$$
Wow Fact 😮 😮 😮
The Lines of Code (LOC) range can vary based on the industry, but general estimates for project sizes are often categorized as follows:
Small Project: Up to 10,000 LOC
Medium Project: 10,000 to 100,000 LOC
Large Project: 100,000 LOC and above
System Designing
When it comes to designing a system, a minimum set of skills is required to proceed with the development of software. This is why I will overview the concept and an example of each diagram used for designing software. They are:
| Aspect | Short Description |
| App Architecture Diagram | Provides a high-level view of the system architecture |
| Use Case Diagram | Actor-based interactions with different use cases within the system. |
| Entity Relationship Diagram (ERD) | Illustrates the data structure for a database. |
| State Machine Diagram | Represents the different states an object can be in, as well as transitions between these states. |
| Relational Schema | Defines the logical structure of a relational database. |
| UML Class Diagram | Displaying classes with their variables and operations and relationships (like inheritance, association, aggregation, composition) among classes. |
| Sequence Diagram | Depicting the sequence of input-output to complete a process between objects. |
| Activity Diagram | Visualizes the flow of control in a system using a flowchart |
Use Case Diagram components and example
The components of this diagram are:
Primary Actor
Secondary Actors
Relations
Association
Generalization
Dependency (Include (mandatory), Exclude (not mandatory))
Examples:

UML Class Diagram
Here are the components:
Examples:



Sequence Diagram

Activity Diagram


State Machine Diagram

App Architecture Diagram (I love this diagram)

Relationship Schema ( I prefer this over ERD )
.png?table=block&id=12ead486-0876-80a7-a6b6-f086b5c612df&spaceId=b6067351-1921-4756-90ef-19d0061185e8&width=1420&userId=&cache=v2)
Development and Documentation
I would not like to add details on this topic as it requires a set of programming skills and concepts of the technical stack and how it works. So here are the basics you must know about it.
Pair Programming
When two developers at a time write higher-level programming instructions for developing software, one can observe the code structure and errors while the other one can write the actual code. It’s used in extreme programming.
Code Refactoring
It’s a way of organizing code where both input and output remain the same but are optimized based on performance, code readability, and reusability. We use SOLID principles for refactoring the code.

Testing and Maintenance
White Box vs Black Box Testing
Here’s a comparison table highlighting the differences between White Box Testing and Black Box Testing:
| Aspect | White Box Testing | Black Box Testing |
| Focus | Focuses on code, internal structures, and paths within the application. | Focuses on input and output without concern for internal processes. |
| Tester's Knowledge | It requires knowledge of programming, algorithms, and the application's internal design. | It does not require programming knowledge; testers can be from a non-technical background. |
| Techniques Used | Techniques include code coverage, control flow, data flow, and path testing. | Techniques include functional testing, usability testing, performance testing, and regression testing. |
| Testing Level | Typically performed at the unit or integration level of testing. | Usually performed at the system or acceptance level of testing. |
| Test Case Design | Test cases are derived from the source code, focusing on paths, loops, and conditions. | Test cases are derived from requirements and specifications, focusing on user interactions and expected outcomes. |
Unit, Integration, Penetration, System Testing
Here’s a comparison table that highlights the differences between Unit Testing, Integration Testing, Penetration Testing, and System Testing:
| Aspect | Unit Testing | Integration Testing | Penetration Testing | System Testing |
| Definition | Testing individual components or modules in isolation to verify that they function correctly. | Testing the interaction between integrated components or systems to identify interface defects. | Simulating attacks on a system to identify security vulnerabilities and weaknesses. | Testing the complete and integrated software system to evaluate its compliance with specified requirements. |
| Focus | Verifying the correctness of a specific piece of code (e.g., functions, classes). | Ensuring that combined components work together as expected. | Identifying security loopholes and vulnerabilities in the application. | Validating the overall behavior, performance, and functionality of the entire system. |
| Level of Testing | Performed at the lowest level of software development (individual units). | Performed after unit testing and before system testing. | Performed at various stages but often after system testing. | Conducted on the entire system after integration testing. |
| Tools Used | Unit testing frameworks (e.g., JUnit, NUnit, pytest). | Integration testing tools (e.g., Postman, SoapUI). | Penetration testing tools (e.g., OWASP ZAP, Burp Suite, Metasploit). | System testing tools (e.g., Selenium, LoadRunner, QTP). |
| Testers | Typically performed by developers. | Developers or testers can perform it. | Usually conducted by security specialists or ethical hackers. | Usually conducted by quality assurance (QA) testers. |
| Test Cases | Tests specific functionalities or methods in isolation. | Tests interactions and data flow between modules. | Tests potential exploits, vulnerabilities, and security controls. | Tests end-to-end scenarios to ensure complete functionality. |
Maintenance
The maintenance strategy was discussed shortly in the system analysis process modeling section.

This image provides a visual overview of the four main types of software maintenance. They are:
Corrective Software Maintenance: This involves fixing bugs or errors that emerge during the software's lifecycle to ensure its correct function.
Preventative Software Maintenance: This type aims to prevent future problems by anticipating potential issues and improving the software's stability and performance.
Perfective Software Maintenance: Enhancements are made to improve the software's functionality and usability based on user feedback or new requirements.
Adaptive Software Maintenance: This involves updating the software to remain compatible with changing environments, such as new operating systems or hardware.
Implementation and Evaluation
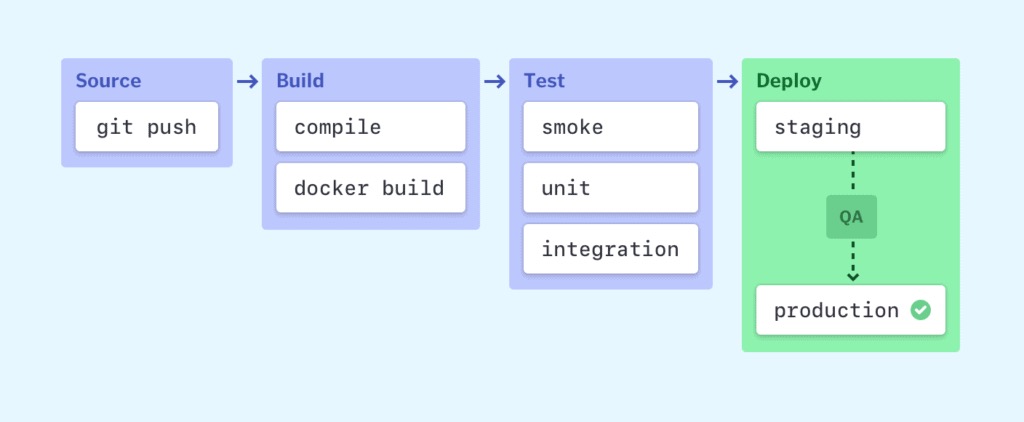
Have you heard the name of CI/CD Pipeline?
A continuous integration and continuous deployment (CI/CD) pipeline is a series of steps that must be performed to deliver a new version of software. CI/CD pipelines are a practice focused on improving software delivery via automation throughout the software development life cycle. Here is an overall picture of how we can implement CI/CD through Jenkins:
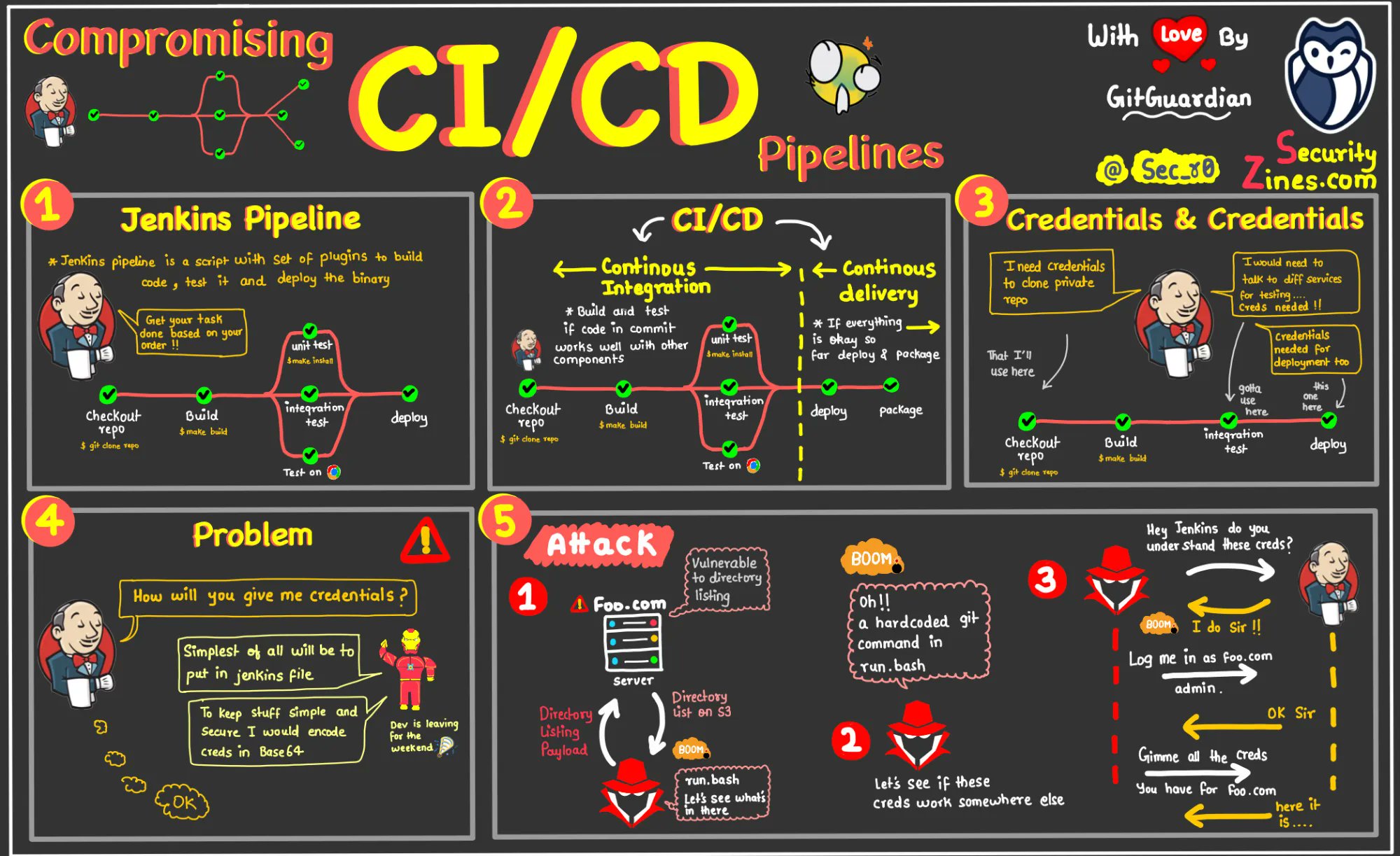
Here are the components of the CI/CD pipelines:
GitHub
The code will be stored in a GitHub repository. This repository will act as the source of truth for the codebase.
Jenkins
Jenkins will be set up on an EC2 instance for Continuous Integration/Continuous Deployment. Jenkins will handle tasks like testing the code and deploying it to production.
Code Deployment Strategy
When changes are pushed to the GitHub repository, Jenkins will automatically trigger a build and test sequence. If successful, Jenkins will deploy the new version to the EC2 instances.
AWS CodeDeploy (Optional)
AWS CodeDeploy could be used for deployment automation to EC2 instances, which allows handling complex deployment scenarios and performing blue/green deployments.
Deployment
As an AWS lover, I would love to discuss a summary of how we can deploy software using AWS servers.
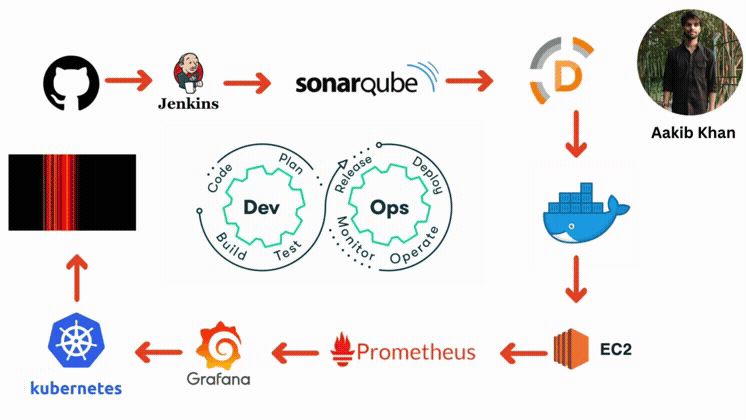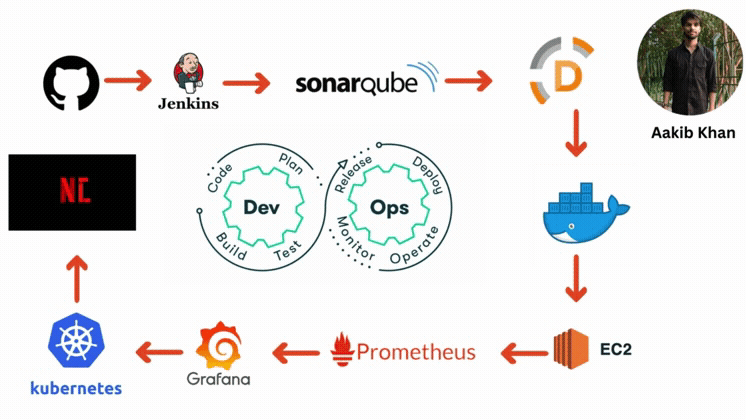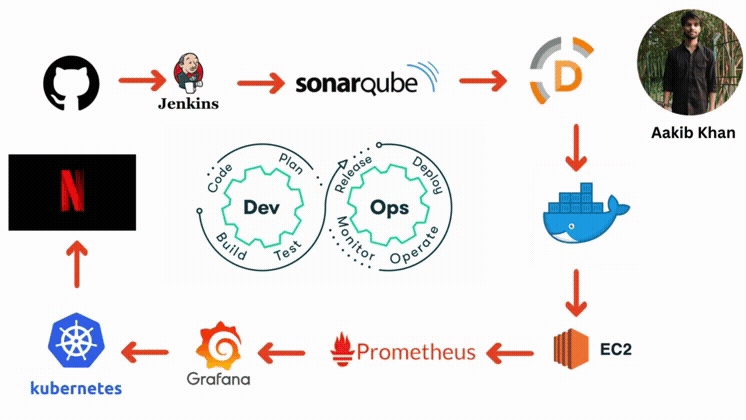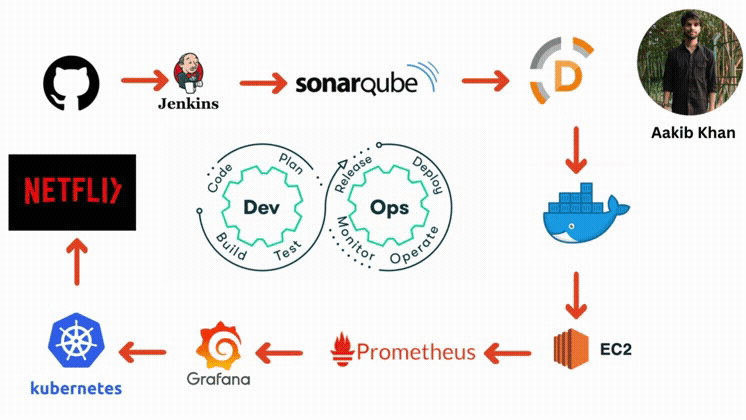
AWS Setup Components Description
Here are the components of AWS setup that is required for deployments:
EC2 Instances
Use EC2 instances to host your Node.js backend. You can set up an Auto Scaling group to handle load changes.
Elasticache
Elasticache (Redis or Memcached) will be implemented for caching. This will help reduce the load on the database and improve response times.
CloudWatch
CloudWatch will be used for monitoring the application's performance and logging. Alarms will be set to get alerts on specific metrics like CPU usage or error rates.
Route 53
AWS Route 53 will manage DNS for the domain, providing reliable and scalable domain name services.
RDS for MySQL
Amazon RDS will manage the MySQL database. It provides automated backups, patch management, and scaling capabilities.
Elasticache
Elasticache (Redis or Memcached) will be implemented for caching. This will help reduce the load on the database and improve response times.
CloudWatch
CloudWatch will be used for monitoring the application's performance and logging. Alarms will be set to get alerts on specific metrics like CPU usage or error rates.
Route 53
AWS Route 53 will manage DNS for the domain, providing reliable and scalable domain name services.
DynamoDB
Amazon DynamoDB is a serverless, NoSQL database service that allows you to develop modern applications at any scale. As a serverless database, you only pay for what you use and DynamoDB scales to zero, has no cold starts, no version upgrades, no maintenance windows, no patching, and no downtime maintenance.
AWS Secrets Manager
It will be used to handle secrets of the Node.js application. It aids in securely storing, managing, and retrieving secrets such as database credentials and API keys.
AWS step-by-step points
Below are detailed step-by-step instructions for each component of your deployment strategy:
1. VPC Initialization
Create a VPC
Create Subnets
Set Up Internet Gateway
Configure Route Tables
2. Connecting Route53 Nameserver
Create a Hosted Zone
Update Domain Registrar
3. Pushing dotenv to AWS Secrets Manager
- Create a New Secret
- Set Permissions
4. Setting up EC2 and RDS in the same VPC (different subnets)
5. Creating Elasticache Cluster for Memcached within the same VPC
6. Adding DB Connection String to AWS SM
7. Installing Amazon-CloudWatch-Agent
sudo yum install -y amazon-cloudwatch-agent
Configure the Agent: Use amazon-cloudwatch-agent-config-wizard to configure metrics and logs to collect and save the configuration file under /opt/aws/amazon-cloudwatch-agent/bin/config.json.
8. Enabling Detailed Monitoring for EC2
9. Setting up CloudWatch Alarms
TO BE CONTINUED…..



